This essay and all new writing is also published in my newsletter which you can sign up for here.
Throughout history, artists have consistently experimented with and pushed the boundaries of what is possible with new technologies in ways that further society’s collective understanding of a technology’s capabilities and use cases. The tinkering of early animators like John Whitney laid the groundwork for the computer graphics and animation industry. More recently, artists like Holly Herndon have experimented with the use of AI voice cloning to allow anyone to generate music with an artist’s voice prompting the public to critically consider artist likeness and content provenance in a world where AI tools can cheaply generate content in the likeness of any artist. Herndon’s work felt particularly prescient earlier this month as a new Drake song sent hip hop communities into a frenzy with its use of AI voice cloning.
Taylor Made Freestyle
Drake and Kendrick Lamar have been slinging disses back and forth in their recent releases and Taylor Made Freestyle is Drake’s latest response.
The most controversial aspect of the track was the use of AI voice cloning to incorporate verses from Tupac and Snoop Dogg with the bulk of the criticism centering around what was suspected to be unauthorized use of the deceased Tupac’s likeness – the track begins with Tupac’s voice rapping a verse goading Kendrick to respond. A week later, these suspicions were confirmed with Tupac’s estate filing a cease and desist against Drake to take down the track.
Drake is intimately familiar with AI generated content having been voice cloned on a viral TikTok track Heart on My Sleeve last spring. The notable difference this time is that he, with his widely recognizable brand and access to broad distribution, is the one certifying a track that prominently uses AI generated content. While it can be argued that the creation of Heart on My Sleeve likely involved a mix of AI generation and non-trivial human effort, it was easier for the public to simply categorize the track as AI generated in the absence of a prominent human with a known brand to anchor to. With Taylor Made Freestyle, not only is the mix of AI generation and non-trivial human effort more recognizable when listening to the track (Drake himself raps one of the verses), but the face of the track is also that of one of biggest music artists in the world. In this case, should we be categorizing the track as AI generated if two out of three of the verses were created using AI? Is a binary categorization of content as AI generated vs. human generated even useful here?
AI generated samples everywhere
The story of the music industry, and the hip hop genre in particular, is a story of sampling – the process of incorporating parts of existing songs into new songs. It only takes a few minutes of browsing on WhoSampled to see how much new music is built on a composition and remix of past music. Samples are everywhere!
Taylor Made Freestyle shows how sampling could evolve in a world of generative AI. Instead of incorporating samples from fixed source music, the track incorporates samples dynamically generated by AI in the style and likeness of specific artists. The use of AI in the sample generation process can be viewed as the next evolution of audio filters and edits applied in a production studio. Artists started off by playing with reverb and distortion, then they dabbled with autotune to alter pitch, and now they are using generative AI to manipulate timbre to convert any sound into their instrument and voice of choice. The first verse of Taylor Made might be rapped by AI Tupac, but converting the verse to use Drake’s voice is just a tweak away in the studio.
If AI generated samples are the next evolution of sampling, we can expect a large portion of songs in the future to contain AI generated samples. Nate Raw compares this future of music with the ChatGPT-ification of text on the Internet – just as traces of ChatGPT can already be found in everything from press releases to blog posts (drink for every instance of “delve” that you see online today), traces of AI will be found in everything from hip hop diss tracks to EDM festival anthems.
Made with AI labels
The likely proliferation of AI generated samples should be kept in mind when considering Meta’s plans to start adding “Made with AI” labels on its platforms (i.e. Facebook, Instagram, Threads) starting in May.
The rollout of Made with AI labels is largely motivated by pressure to establish defensive measures against misinformation driven by photorealistic AI deepfakes during the 2024 election season. The system is likely to undergo plenty of iteration over time, but as-is it already highlights some of the challenges in deploying defensive measures against negative uses of generative AI without stymieing experimentation with positive uses.
Does “Made with AI” mean that the content was entirely generated using AI? Or does it mean that the content includes some AI generated portions? If the intent is for the label to convey latter, will consumers interpret the label in that manner or will they still interpret the label as the former? This last question is particularly important because there is clearly a difference in an image generated via Midjourney and that same image used as a canvas for an artist to overlay additional aesthetic edits with other tools. Similarly, there is also clearly a difference between a purely AI generated song from Suno vs. a song that is the composition of AI generated samples and human generated sounds. All of these examples can be categorized as content with AI generated portions. But, if all of these examples are labeled as “Made with AI” and consumers end up interpreting the label as an indication that the content was entirely generated using AI then artists that incorporate AI in a larger creative process would be lumped in with a sea of other commoditized AI outputs in the eyes of the consumer. Furthermore, a “Made with AI” label will lose utility as traces of AI make their way into the majority of content – the label probably won’t be very useful if most content has it.
All that said, another Meta press release hints at a future direction that could be more productive:
While the industry works towards this capability, we’re adding a feature for people to disclose when they share AI-generated video or audio so we can add a label to it. We’ll require people to use this disclosure and label tool when they post organic content with a photorealistic video or realistic-sounding audio that was digitally created or altered, and we may apply penalties if they fail to do so.
Setting aside the contents of the label for a moment, the most interesting aspect of this approach is that it would create an incentive for creators to make transparent assertions about the provenance of their content and only applies penalties if those assertions are found to be false. The use of AI is certainly an important assertion to include, but ultimately what is most important is to ensure consumers have sufficient context based on content provenance. This context can help mitigate misinformation if the consumer, as an example, knows that the content originated from a camera at a specific time and place and not an AI image generation tool. This context could also help content using AI generated samples stand out in a sea of commoditized AI outputs if the consumer, as an example, knows that the content originated from a novel workflow that combines AI and human efforts.
There are plenty of open questions and challenges here. Can the friction involved in making these assertions be reduced and automated? Is there a UI that can surface this information in a way that meaningfully influences consumer behavior? Meta suggested penalizing inaccurate assertions of provenance – is it possible to also create an ecosystem that rewards accurate assertions of provenance from both the creator and others? But, relative to the binary categorization of content as AI generated vs. human generated which feels too reductive and constraining, this seems to be a more promising direction to explore for fostering a dynamic ecosystem of creative content while minimizing the harm of AI powered misinformation.
Along with questions from an initial dive into the 2.0 spec.
This essay and all new writing is also published in my newsletter which you can sign up for here.
We’re just a few months into 2024 and there does not appear to be any sign of slow down in generative AI advancements with the quality of synthetic media increasing everyday across all modalities. As election seasons progress throughout the world, we can expect to see an uptick of synthetic deepfakes making their rounds online and with it increased concerns of how to distinguish between physical and AI generated realities.
In the past few months, C2PA, touted as a technical standard for establishing the provenance of digital media, has received increased attention as a potential solution with a number of tech companies including Meta, Google and OpenAI shipping integrations or announcing plans to do so. Adobe has been leading the charge promoting the use of Content Credentials, built using C2PA, as “nutrition labels” that can be used by consumers to understand the provenance of media and most importantly distinguish between real media and AI generated deepfakes. At the same time, the approach has been criticized for being too easily bypassed by bad actors and insufficient for proving provenance.
As the standard is evaluated and adopted, it is worthwhile asking: what are the exact problems that the C2PA standard actually solves for and what does it not solve for?
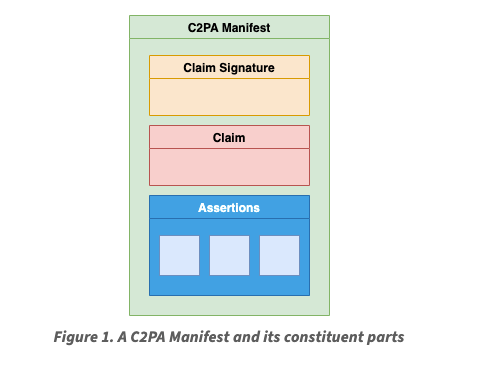
The Coalition for Content Provenance and Authenticity (C2PA) addresses the prevalence of misleading information online through the development of technical standards for certifying the source and history (or provenance) of media content.
This specification describes the technical aspects of the C2PA architecture; a model for storing and accessing cryptographically verifiable information whose trustworthiness can be assessed based on a defined trust model. Included in this document is information about how to create and process a C2PA Manifest and its components, including the use of digital signature technology for enabling tamper-evidence as well as establishing trust.
My simplified explanation of C2PA in a single sentence:
C2PA is a standard for digitally signing provenance claims about a media asset (i.e. image, video, audio, etc.) such that any application implementing the standard can verify that a specific identity certified the claim.
A claim consists of a list of assertions about an asset which can include:
The creator’s identity
The creation tool (i.e. camera, Adobe Photoshop, OpenAI’s DALL-E 3)
The time of creation
The “ingredient” assets used and actions performed on them during creation
A key property of C2PA is that a claim is directly tied to an asset and can travel with the asset regardless of where the asset is used whether it be on a social media platform (i.e. Facebook, Instagram) or a chat application (i.e. Whatsapp).
A claim is digitally signed by the hardware or software used to create the asset. The signature and claim are then packaged up into a manifest file that can be embedded into the asset and/or stored separately for later retrieval. An application can then fetch the manifest for an asset, verify the signer and evaluate the trustworthiness of the signer based on the requirements of the application. For example, Adobe’s Content Credentials Verify tool checks uploaded assets for a manifest and if the application trusts the signer the UI will display a Content Credentials badge.
But, how would an application know if the assertions in a claim are actually correct and that an asset was actually created using, for example, a camera and not a generative AI model? The short answer is that an application wouldn’t – the C2PA manifest for an asset alone is insufficient to guarantee that claim’s assertions are correct. So, what’s the point of a signed provenance claim if we can’t guarantee that its assertions are true?
Note: A C2PA workflow can provide stronger guarantees around the correctness of certain assertions, such as the creation tool, if a claim is signed by hardware with a secure enclave. In 2023, Leica released a camera with C2PA signing support which would allow the camera itself to sign a claim asserting that the specific camera model was used to take a photo. However, since hardware with C2PA signing support is not widely deployed as of early 2024, the rest of this post will focus instead on scenarios where claims are signed by software.
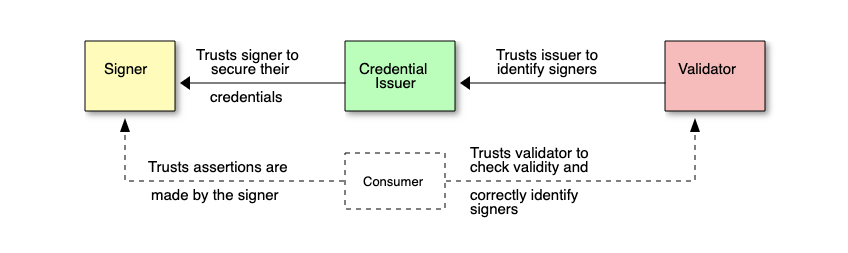
The trust model defined in the C2PA spec explicitly states that a consumer (both the human and an agent acting on behalf of the human) is able to verify the identity of the signer for a claim, but must decide on their own whether the claim’s assertions are correct using the signer’s identity and any other available information as evidence. Given this, the criticism that the use of C2PA alone would be unable to actually establish irrefutable provenance of an asset is fair – you cannot guarantee that a provenance claim for an asset accurately represents the asset’s provenance just based on signature verification alone.
What does C2PA solve for?
The problem that C2PA actually solves for is establishing non-repudiable attribution for provenance claims about a media asset in an interoperable manner. The claim signature links the claim to a specific identity which establishes attribution and non-repudiation – anyone can verify that the identity made the claim and not someone else. The standardized data model for the manifest that packages up a claim and its signature allows any application supporting the standard to process a claim and attribute it to an identity which establishes interoperability.
Is all of this still useful if the claim may not represent the asset’s true provenance? I would argue yes.
Today, as an asset is shared and re-shared across different platforms, the authentic context for the asset is lost.
Consider the following scenario: a photo taken from country A could be published by a news organization on social media and then copied and re-shared across accounts and platforms such that a consumer is misled by a third party to believe that the re-shared photo shows an event happening in the conflict zone of country B.
When the news organization publishes the photo they are making a claim that the photo was taken at a specific time and place. The claim is a part of the authentic context defined by the news organization. The problem is that this context is lost as the photo travels around the Internet making it more difficult for a consumer to determine who the photo was originally published by and allowing others to make claims about the photo that sow confusion.
A signed claim would not irrefutably prove that the photo was taken at a certain time and place, but it would preserve the authentic context for the photo – it would preserve the claim that the news organization made about the photo’s provenance. Consumers would still have to judge for themselves whether they trust the news organization’s claim, but they would know for certain who the photo was originally published by and that the claim was made by the news organization and no one else which keeps the news organization accountable for their claims.
Issues to address
A few issues come to mind that are worth addressing:
Many platforms strip metadata, which would include C2PA manifests, from uploaded media assets
Potential solutions to explore:
Platforms can retain manifests for uploaded assets
Publishers can store manifests in a public registry such that they can be looked up for assets even if platforms strip the manifest for uploaded assets
Bad actors can strip the C2PA manifest before uploading an asset
Potential solutions to explore:
Platforms can start flagging assets without manifests and/or prefer assets with manifests in algorithmic feeds
The challenge here is that most assets will not have manifests initially similar to how most websites did not have SSL certificates during the early days of the HTTP -> HTTPS transition so before this becomes a viable approach it will need to be much easier for publishing tools to create manifests. The more aggressive warnings shown by browsers for websites without SSL certificates were enabled in large part by services like Let’s Encrypt dramatically reducing the friction in obtaining a SSL certificate.
Bad actors can create their own C2PA manifest with incorrect assertions for an asset
Potential solutions to explore:
Platforms can use trust lists and scoring to evaluate whether the signer should be trusted in a specific context
Questions
A few questions I am thinking about:
How will the C2PA trust list that initial validator implementations will use by default be decided?
The current version of the C2PA spec uses a PKI based on x509 certificates. A claim signer must have a signing certificate and a validator will check that the signing certificate fulfills one of the following conditions:
The signing certificate can be linked back through a chain of signatures to a root Certificate Authority (CA) certificate that is on the default C2PA list of trusted CAs
The signing certificate can be linked back through a chain of signatures to a root CA certificate that is on the validator’s custom list of trusted CAs
The signing certificate is on the validator’s custom list of trusted signing certificates
The members of the default C2PA trust list will have a lot of power because claims signed by signing certificates that they issue will be trusted by default by any C2PA software.
How will major content distribution platforms (i.e. Facebook, Instagram, etc.) with C2PA validator integrations decide on the trust anchors to add to their trust list?
The platforms will be able to customize their trust lists and specify additional CAs (and possibly ignore CAs on the C2PA trust list?) that they trust. But, in practice, will they just use the default C2PA trust list?
How will creator tools get signing certificates that are accepted by validators?
Will developers have to go through a manual approval process? Will this go through a small number of CAs or will there be many CAs that issue different types of certificates that reflect the type of validation performed similar to Domain Validated vs. Organization Validated SSL certificates? Will automated services be possible similar to what Let’s Encrypt did for SSL certificate issuance?
The claim signer is expected to be the hardware or software used to create an asset and not the creator themselves. In certain cases, could it make sense for the claim signer to be the creator themselves?
The Creator Assertions Working Group (CAWG) is working on standardizing how a creator can create a signed assertion documenting themselves as the asset creator in a C2PA claim. But, this results in an additional signature separate from the claim signature. The intent seems to be for the hardware or software based claim signer to verify this identity assertion before including it in the claim. This workflow makes sense in the scenarios where the hardware or software is not completely controlled by the creator i.e. a camera with a secure enclave, a backend service for a web application. However, this workflow makes less sense for non-hardware, locally run creator tools (applies to many open source tools) without a backend that can secure a private key for signing. In this scenario, since the creator is in complete control of the tool, it seems like it would make more sense for the claim signer to just be the creator rather than having a separate claim signature and an identity assertion – who else would produce the claim signature besides the creator?
Can identity assertions preserve privacy?
The CAWG seems to be exploring the use of privacy preserving techniques for future versions of the spec that are compatible with WC3 Verifiable Credentials. There is also interesting in the wild work happening in other communities that seems worthwhile to consider learning from. The 0xPARC community has established its own Proof Carrying Data (PCD) framework that uses ZKPs to create and compose privacy preserving claims about an identity – perhaps there is an opportunity to leverage some that work here.
How will content optimization pipelines that alter the hash of data without altering visual content (i.e. image rendering, video transcoding, etc.) be affected by C2PA adoption?
The C2PA spec allows service providers to create their own signed claims with assertions about the computation performed on an input asset which is referenced in the manifest. However, this would require service providers to implement C2PA support which likely would only happen if they are pressured by platforms to do so. A platform might just show users an optimized version of an asset with a hash that does not match the one in a C2PA manifest. The argument in defense of this practice would be that the user is trusting the platform anyway and the platform knows that the optimized asset it is showing users visually corresponds to the one referenced by the hash in the manifest.
How should we think about C2PA vs. NFT standards like ERC-721?
While C2PA and NFT standards both have a design goal of establishing attribution for provenance claims in an interoperable manner, they also differ in a number of ways:
The C2PA spec is focused on standardizing how to make assertions about the lifecycle of a media asset while most NFT standards are more generic with their treatment of asset metadata.
The C2PA spec optionally allows manifests to be timestamped by centralized Time Stamp Authorities while NFT standards assume that metadata is timestamped by a blockchain.
A C2PA manifest records a provenance claim while a NFT records a provenance claim and links it with a transferrable/tradeable asset.
At this point, C2PA and NFT standards appear to be more likely to be complements as opposed to substitutes.
Can C2PA adoption benefit from the consumer crypto wallet infrastructure that has been deployed in the past few years?
In order for creators to create identity assertions for C2PA claims, they will need consumer friendly software for signing. While there are still a number of UX/UI improvements that need to be made, the consumer wallet software that the crypto industry has funded in the past few years arguably represents the most sophisticated deployment of consumer digital signing software out in the wild.
How does X’s community fact-checking system actually work?
Image generated by DALL-E 3.
This essay and all new writing is also published in my newsletter which you can sign up for here.
After Elon’s decimation of the X/Twitter’s previous content moderation systems, Community Notes (formerly known as Birdwatch) emerged from the ashes as one of the only members of the content moderation old guard that survived the company’s ownership transition
The community fact-checking system relies on existing X users to write and rate notes that add helpful context to misleading posts. In the current era of declining trust in centralized institutions for fact-checking politically polarizing topics, the system is designed to avoid relying on any single institution to define what is or is not a misleading post. Instead, it publicly attaches notes written and rated by users to posts based on an open source and publicly documented algorithm. While crowdsourced content moderation is not a new idea with various implementations deployed on other platforms (i.e. Wikipedia, Reddit), Community Notes uses a unique implementation that attempts to only surface notes if they are rated positively by users with diverse viewpoints (i.e. on the political spectrum).
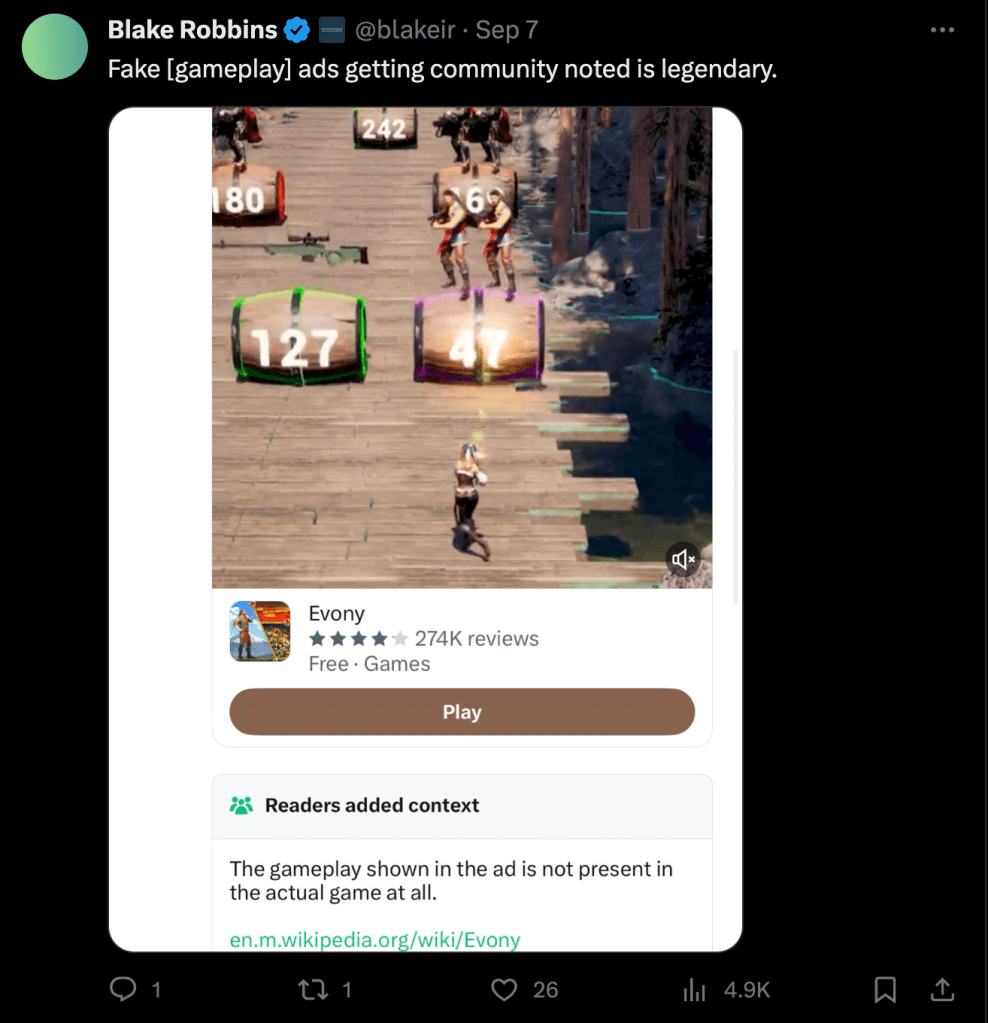
First, the good news. On numerous occasions, Community Notes has successfully surfaced notes with very helpful context on misleading posts!
I think its probably fair to say that we’re collectively better off knowing that a game ad is a scam. And we’re also probably better off knowing that Elon did not unilaterally remove the verified badge from the New York Times’ profile in response to recent botched reporting even if it would make for a sensational story.
Now, the bad news. On numerous occasions, Community Notes has also surfaced notes with incorrect information:
On the lighter side, a post referring to Taylor Swift’s bodyguard’s Israeli military service was flagged by a note claiming the man is not her bodyguard. The man was later reported to in fact be her bodyguard.
On the more serious side, a post with a video of an Hamas attack on Israelis was flagged by a note claiming the video was years old and not taken in Israel. The video was later reported to be real.
Making matters worse, even though X has lengthy documentation and a research paper describing the open source algorithm for ranking and surfacing notes, it is not clear how many people actually understand or trust how the algorithm is supposed to work.
However, the system at least previously employed a technique known as bridge-based ranking to favor notes that receive positive interactions from users estimated to hold differing viewpoints. Still, how this works is not clear to at least some Community Notes contributors.
“I don’t see any mechanism by which they can know what perspective people hold,” Anna, a UK-based former journalist whom X invited to become a Community Notes contributor, tells WIRED. “I really don’t see how that would work, to be honest, because new topics come up that one could not possibly have been rated on.”
The reality is that the average user of X or Community Notes is not going to read pages of LaTeX equations and algorithm specifications to understand why a note is or is not surfaced on a post when they can just yell at Elon instead. At the same time, while it is unrealistic to expect the average user to understand nitty gritty technical details, there is value in equipping more people with a high level understanding of what the algorithm attempts to accomplish and the inputs that it depends on. If Community Notes (or any other community content moderation system for that matter) expects to build more user trust than the centralized institutions they aim to improve on then a prerequisite is to help people understand why their algorithmic approach should deserve that trust which requires more than transparency via open source code and documentation. It requires a diverse array of explanations for the diverse array of users that will engage with and be impacted by the system each constructed using terms and language appropriate for a specific target audience.
With this in mind, the aim of this essay is to make a small contribution to the array of explanations by answering the question of how does the Community Notes algorithm work under the hood?
How Community Notes works
At this point, we’re all accustomed to personalized algorithmic feeds on every social media platform that act as a filtered lens to view the stream of social consciousness flowing through the platform. On X, the For You feed gives each of us a unique view on what is happening. A side effect of this unique view is that the notion of shared truth becomes fuzzy because the whole point of the For You feed is to create a stream of information tuned to you which need not be the same as that of your next door neighbor. Concerns of society trending towards a world without any shared truth are abound.
Community Notes breaks from this trend. A note attached to a post is seen by everyone on X that sees the post. There is no personalized filtering here. The same note that is seen by coastal elites dunking on each other over the latest current thing is seen by your grandma that is still asking you to accept her Facebook friend request. But, if there is no personalized filtering, then how do you determine which notes to attach to a post for everyone to see? I probably shouldn’t be able to arbitrarily attach notes to Elon’s posts asking his followers to send me 1 ETH in exchange for 2 ETH.
The Community Notes algorithm only attaches a note to a post if the note is deemed to have a high likelihood of being seen as helpful by a broad set of users with diverse viewpoints. Thus, the core problem that Community Notes attempts to solve is: how do you predict whether a note will be helpful to a broad set of users with diverse viewpoints?
Before diving into how Community Notes attempts to solve this problem, let’s take a step back and consider a simpler version of the problem. If we put aside the “helpful to a broad set of users with diverse viewpoints” requirement and squint, the end result feels similar to the recommendation problem of: how do you predict whether a note will be liked by a user?
You’ve almost certainly benefited from solutions to versions of this recommendation problem in your day-to-day life:
TikTok answers the question of how do you predict whether a video will be liked by a user so that you can endlessly scroll through your feed.
Netflix answers the question of how do you predict whether a movie/show will be liked by a user so that you never run out of content to binge watch.
Spotify answers the question of how do you predict whether a song will be liked by a user so that you can find new music to listen to.
The general form of the these recommendation problems is: “how do you predict whether an item will be liked by a user?”. And it turns out there is a general machine learning solution to this problem called collaborative filtering.
Collaborative filtering
The core idea of collaborative filtering is to predict whether a user will like an item by using data on whether similar users like the item.
What does this look like? As of last summer, I had never listened to Lindsey Sterling before. But, my friend Ian and I both really like orchestral film scores, and he happened to be listening to Sterling’s version of the main theme from The Dark Knight Rises on repeat around that time. Not all of Sterling’s music exactly fits the category of orchestral film scores, but it would be a reasonable bet for Spotify to recommend Sterling to me just based off of Ian’s preferences and our previous overlap in taste.
Let’s walkthrough how a very simplified version of Spotify might make that recommendation. First, we can visualize user preferences in the following table:
Each row in this table corresponds to a user and each column corresponds to an artist. If the cell contains a 1 then the user for that row likes the artist for that column. The cell for Yondon/Ramin Djawadi contains a 1 so Yondon likes Ramin Djawadi. The cell for Ian/Drake contains a -1 so Ian dislikes Drake. A blank cell indicates that the user has not explicitly expressed whether they like or dislike the artist. The objective is to fill in the blank cells based on the already filled in cells.
While we don’t know the specific reasons why each user likes a particular artist, we can assume that they exist and we just don’t know what they are. A simplified way to think about these reasons is: I like characteristic X, Y and Z and this artist exhibits a lot of characteristic X, Y and Z therefore I like the artist. In the context of music, these characteristics might be X = contains violin, Y = contains piano and Z = high energy. The technical term for one of these unknown characteristics is a latent factor.
Each user and artist has a vector of latent factors which can be used to determine how good of a match they are. The larger the numerical value for a latent factor, the more prominent the characteristic – for a user, this would mean a stronger preference for the characteristic (i.e. music that contains violin) and for an artist, this would mean a strong expression of the characteristic. A compatibility score for a user and artist can be computed using the dot product of their latent factors which is the sum of the product of each of the factor values. The intuition here is that since the largest dot product is achieved if the latent factor values for both the user and artist are large we can use the dot product as a singular value to represent how compatible the user and artist are.
Suppose:
Yondon’s latent factors are represented by the vector [0.8, 0,9, 0.7]
Sterling’s latent factors are represented by the vector [1.0, 0.6, 0.8]
Rick Ross’ latent factors are represented by the vector [0.2, 0.5, 0.8]
The dot product for Yondon and Sterling is (0.8 * 1.0) + (0.9 * 0.6) + (0.7 * 0.8) = 1.9. Meanwhile, the dot product for Yondon and Rick Ross is (0.8 * 0.2) + (0.9 * 0.5) + (0.7 * 0.8) = 1.17. Based on these dot product values, we can infer that Yondon and Sterling would be more compatible than Yondon and Rick Ross.
But, we wouldn’t want to just rely on the dot product of latent factors for predicting whether a user would like an artist because the dot product only tells us how compatible a user and artist are based on preferences for characteristics without capturing whether a user generally likes or dislikes most artists and whether an artist is generally liked or disliked by most users. If Ian has similar preferences as me and he generally is neutral on most artists, then it could make sense to recommend artists that he likes to me. But, if Ian generally likes most artists, then it might not make as much sense – I could end up being recommended an artist that he likes not because of characteristic based compatibility, but because he just likes a lot of artists. Additionally, if Sterling is liked by Ian and she is generally neutral for most users, then it could make sense to recommend her to me. But, if Sterling generally is liked by most users, then it might not make as much sense – I once again could end up being recommended an artist based on general positive sentiment instead of characteristic based compatibility.
In order to capture this additional information, we can use a numerical value to represent a user’s likelihood to like most artists and an artist’s likelihood of being liked by most users. The larger the numerical value, the more likely a user is to like most artists and an artist is of being liked by most users. The technical term for this value is a bias or intercept (the Community Notes documentation uses the term intercept so we will use that here as well). Each user and artist has an intercept value which can be added to the dot product of their latent factors to output a compatibility score that not only captures compatibility based on characteristics, but also the user’s general sentiment towards artists and the artist’s general reception amongst users.
Now, suppose:
Yondon is a grouch and generally dislikes new music he discovers so he has an intercept of -0.6
Sterling is a hit with almost everyone that discovers her so she has an intercept of 0.7
Rick Ross is polarizing and is a hit or miss for users that discover him so he has an intercept of 0.1
The updated score score for Yondon and Sterling is 1.9 + (-0.6) + 0.7 = 2. Meanwhile, the updated score for Yondon and Rick Ross is 1.17 + (-0.6) + 0.1 = 0.67. Based on these scores, we can not only infer that Yondon and Sterling would be more compatible than Yondon and Rick Ross, but that the former is also much compatible than the latter when also considering the user’s general sentiment towards artists and the artist’s general reception amongst users.
So, we know that the latent factors and intercept values for users and artists can be used to predict compatibility, but we’re still left with a problem: we don’t know what the actual latent factors and intercept values for users and artists are! This is where the learning part of machine learning comes into play. We need to create a model that learns parameter values (i.e. latent factors and intercept values for users and artists) so they can be used to output predictions of whether a user would like an artist.
At a high level, the training of the model consists of:
Set the parameters to initial values (i.e. random).
Repeat the following using a gradient descent iterative optimization algorithm:
Calculate the prediction for each user/artist pair using the parameters.
Calculate the loss which is a function of the difference between the actual rating for a user/artist pair and the prediction.
Adjust the parameter values based on the loss with the goal of decreasing the loss in the next iteration.
This approach to collaborative filtering is called matrix factorization.
Community Notes core algorithm
We can also use matrix factorization to solve the problem “how do you predict whether a note will be liked by a user?”. The only difference is that artists will be replaced with users as shown in the table below:
Each row in this table corresponds to a user and each column corresponds to a note. A 1 indicates a user rated a note as helpful, a 0 indicates unhelpful and a 0.5 indicates somewhat helpful.
But, Community Notes is not designed to give personalized note recommendations so the goal is not to just predict whether a note will be liked by a user. We previously tabled the “helpful to a broad set of users with diverse viewpoints” requirement which still needs to be addressed.
The key insight that the Community Notes algorithm builds upon is that if a model is trained to explain note ratings as much as possible using user and note latent factors vs. intercept values then the model is encouraged to learn note intercept values that represent a note’s likelihood to be rated helpful by a broad set of users with diverse viewpoints. Recall that the dot product of latent factors represent compatibility based on specific characteristics. Given that a significant percentage of posts on X focus on politics and news, the specific characteristics that cause a user to rate a note as helpful or unhelpful regardless of how it is received by the majority of users might look like: aligns with a belief of the political left, aligns with a belief of the political right, etc. In other words, the user latent factors would end up capturing a user’s strength of preference for a political viewpoint and the note latent factors capture a note’s strength of expression of a political viewpoint.
Since the numerical values for latent factors can be positive or negative, we can visualize the range of values for a latent factor along an axis where moving towards the left means more negative values and more alignment with some viewpoint A while moving towards the right means more positive values and more alignment with some viewpoint B.
While viewpoints A and B might represent the political left and right respectively, the model does not actually explicitly associate viewpoint A or B with any particular definitions. However, just knowing whether users and notes align with A or B is sufficient for understanding whether a user and note are compatible based on viewpoint.
The intuition is that if a model trained to try to first explain note ratings using viewpoint compatibility using the user and note’s latent factors then:
A note with many helpful ratings that are mostly explained by viewpoint compatibility would be more likely to receive a small intercept value indicating that it is not broadly helpful and the note is instead only deemed as helpful if the note and rater are viewpoint compatible.
A note with many helpful ratings that are not mostly explained by viewpoint compatibility would more more likely to receive a large intercept value indicating that it is broadly helpful and the note is deemed as helpful even when the note and rater are not viewpoint compatible.
And if the note intercept value has the property where it is large when the note is broadly helpful regardless of viewpoint compatibility, it can serve as a “helpfulness score” that predicts how helpful a note will be to a broad set of users with diverse viewpoints!
The Community Notes core algorithm can actually be viewed as a variant of the standard matrix factorization used for traditional recommendation systems with two important changes:
The model is trained to mainly explain existing note ratings based on the dot product of latent factors before adjusting the intercept values.
The output from the model that we care about is the note’s intercept value instead of the actual predicted rating from the model.
1 is accomplished by using a technique called regularization to apply a larger penalty to the training loss for adjustments to the intercept values vs. adjustments to the latent factors. We can see how regularization is applied in the loss function definition:
The first term is the “base loss” which is calculated based on the difference between the actual and predicted ratings.
The second term contains the intercept values which are multiplied by a regularization value that is 5x larger than that of the third term which corresponds to applying a greater penalty on the loss for the intercept values.
The third term contains the latent factor values which are multiplied by a regularization value that is 5x smaller than that of the second term which corresponds to applying a smaller penalty on the loss for the latent factor values.
The result is that during training, the model will focus on adjusting latent factors to accurately predict existing ratings and only adjust intercept values as is needed as a last resort.
In summary, at a high level, the core algorithm is:
Set the parameters to initial values (i.e. random).
Repeat the following using a gradient descent iterative optimization algorithm:
Calculate the prediction for each user/note pair using the parameters.
Calculate the loss which is a function of the difference between the actual rating for a user/note pair and the prediction.
Adjust the parameter values based on the loss with the goal of decreasing the loss in the next iteration.
For each note, assign the its intercept value as its “helpfulness score”.
While Community Notes also incorporates additional mechanisms that are layered on top of this core algorithm, the ability for the system to incorporate diverse viewpoints when assessing whether a note will be helpful to a broad set of users comes from this core algorithm.
Protocols encode the rules of engagement that coordinate the exchange of a service between a global supplier and a global consumer.
Chris Burniske (Placeholder Capital)
One question that comes to my mind given the above definition: are the rules of engagement globally defined or locally defined per service relationship?
In many blockchain based protocols, the rules of engagement are defined at a global level (i.e. all nodes follow the same consensus rules). While this protocol architecture might be ideal in many cases, is it the only viable architecture? Are there alternative ways to define rules of engagement that might be more appropriate for certain classes of protocols?
Service Agreements
Jorge from Aragon presents one such alternative:
An example of using an NFT representing a liability enforced by Aragon Court.
In this approach, the rules of engagement are locally defined because liabilities, that essentially represent service agreements for a capability offered by a provider, can be issued on a per service relationship basis. Some implications of this include:
A single provider can own many liabilities
A single capability offered on the network can be associated with different liabilities
Instead of the protocol supporting a single capability associated with a single liability, this protocol structure can support multiple capabilities and multiple liabilities. There are examples of service protocols exploring this design path and reasons why this might be desirable include:
Some consumers might require stricter service agreement terms than others i.e. heavier penalty for a violation of the agreement
Some consumers might prefer to use different dispute resolution mechanisms in service agreements depending on their trust/security requirements
While a liability might need to be anchored on-chain in order to enforce a dispute resolution mechanism in the event of a violation of the service agreement, a capability can be defined off-chain as long there is a way to determine that a consumer and provider mutually agreed to associate the capability with a particular liability for a transaction. One way to accomplish this would be for both parties to cryptographically sign a data payload that references the off-chain capability, the on-chain liability and any transaction data that might be needed in the event that a dispute is required. The signatures of both parties along with this data payload function as authenticated evidence of an established mutual agreement between parties for a transaction that can be presented to parties external to the transaction if needed. An additional benefit of parties binding a capability with a liability on per service relationship, the duration of which might only be for a single transaction, is increased flexibility to experiment with and upgrade to different agreement structures that could incentivize different types of behavior in providers.
A service protocol that supports off-chain capabilities and on-chain liabilities allows consumers to exchange with providers based on not only the capabilities offered, but also the liabilities owned (and which ones they choose to use to secure their capabilities) the end result being a network with a diverse set of rules of engagement depending on the preferences and requirements of consumers and providers. But, this brings up a follow up question: in a network with a variety of liabilities and capabilities, how do parties determine if service was delivered according to different agreement terms especially if it is not clear if there are objective, algorithmic and deterministic verification method for certain capabilities?
Subjective Dispute Resolution
This follow up discussion to Jorge’s tweet points at one possible answer:
Absolutely.
In terms of off-chain verification, the end service would have to understand NFTs and publish audit logs to allow the underlying capability to be secured by something like Aragon Court.
Aragon Court is as a subjective dispute resolution system (Kleros is another) that incentivizes participants to determine whether a human readable agreement was violated or not and then report the decision on-chain. Introducing a subjective dispute resolution system into a service protocol may incite a negative initial reaction. Doesn’t this run counter to the goal of eliminating human judgement, which can be manipulated, misguided, etc., from the types of permissionless, unstoppable digital marketplaces that service protocols seek to enable? We want objective, algorithmic and deterministic methods for securing service protocols! We want to trust code not humans! This sentiment is understandable.
However, it is worth considering whether there are cases where human powered subjective dispute resolution might actually be more practical than or preferable to objective verification methods that are common in blockchain based protocols today. Consider an image/video transformation service. The goal of the service is to apply a set of permissible transformations to an image/video such that the end result still faithfully represents the content of the original image/video. There are cryptographic techniques for verifying that this service is delivered correctly, but they can be quite computationally expensive which may or may not make sense depending on the requirements of a consumer. The next best solution is to use statistical techniques – for example, a machine learning model can be constructed to classify authentic pairs of images/videos. But, statistical techniques have non-negligible error rate meaning that they will never be 100% accurate. Interestingly, while a machine might mistakenly classify a transformed image/video as authentic or inauthentic, it is actually quite easy and fast for a human to evaluate whether a transformed image/video actually contains the same content as another image/video.
In the cryptography field, one of the desired properties of verifiable computation systems is succinctness meaning that verification is substantially faster/cheaper than running the computation itself. In this case, the system could actually achieve succinctness by using a human verifier! Clearly, it would not be practical for a human to be continuously verifying service delivery, but this observation that a human can be a much more accurate/efficient verifier than a machine for certain types of services might be an indication of that there is potential in designs that introduce human verification only when absolutely needed. Perhaps that is where using subjective dispute resolution systems such as Aragon Court to report the outcomes of human verification on-chain could be useful.
Nowadays, two-factor authentication is standard security best practice for user authentication in applications. Requiring a second factor for authentication besides a password diminishes an attacker’s ability to compromise a user’s account via techniques such as phishing. A common second factor is a one-time password (OTP) that is generated by a mobile application such as Google Authenticator or Duo.
A Universal 2nd Factor (U2F) hardware token is another second factor that is growing in popularity. Users complete an authentication workflow by pressing a button on an inserted USB-based hardware token that communicates with the user’s browser. Check out Yubico’s blog post for a comparison of U2F vs. OTP based two-factor authentication.
In this post, we will explore the cryptographic protocols used by U2F hardware tokens under the hood. Additionally, we will review some interesting extensions for improving hardware token resiliency against supply chain attacks as described in a paper by Dauterman et. al.
U2F Registration
U2F uses a challenge-response protocol in which a token responds to challenges sent by the server with the user’s browser serving as a intermediary that forwards messages between the token and server. Prior to using the token for authentication, a user must first register the token with the server.
The registration process consists of the following steps [1]:
The server sends an application ID.
The token generates an identity ECDSA key pair for the given application ID. Tokens use a unique ECDSA key pair during authentication for each unique identity. The token also generates a key handle.
The token sends the identity public key and the key handle to the server.
In order to reduce the storage used on the token (which has very limited storage to begin with), in step 2, the token does not store the identity secret key and instead derives it using a key handle and a keyed one way function. Yubico generates identity secret keys using the application ID and a nonce as parameters in HMAC-SHA256 keyed by a global device secret. The nonce and a MAC created using the application ID and the device secret compose the key handle [2]. The server stores the key handle alongside the identity public key.
U2F Authentication
The authentication process consists of the following steps [3]:
The server sends an application ID, challenge and key handle.
The browser also includes an origin and TLS channel ID when forwarding the server’s message to the token.
The token uses the key handle to derive the identity secret key for the application ID.
The token increments a local counter that tracks the number of authentications performed using the token.
The token sends the identity secret key’s signature over the application ID, challenge, origin, TLS channel ID and counter value to the server.
If the signature is valid for the registered identity public key, the origin and TLS channel ID are correct and the counter value is valid, the server accepts the token’s response.
In step 2, since the key handle is scoped to the application ID, a token can determine if a received key handle is valid for a particular application ID. For example, using Yubico’s key generation scheme, a token would use the MAC included in the key handle to verify that the nonce was originally generated by the token for the given application ID. Then, the token would pass the nonce and application ID into HMAC-SHA256 keyed by the device secret to derive the identity secret key [2].
The token uses a local counter to defend against device cloning attacks. If an attacker is able to physically clone a token, the counter value would be same on both copies as the counter is only incremented during authentication. As a result, if a server sees a particular counter value more than once, it can infer that a device has been cloned and then block further authentication attempts [3].
The browser’s inclusion of the origin and TLS channel ID in step 2 followed by the server’s check of these fields in step 6 create phishing and man-in-the-middle (MITM) attack protection. The server can check that the same browser origin is included in the token’s signed response to confirm that a token did not sign data provided by a phishing site that differs from the origin that the server first communicated with. The server can also check that the same TLS channel ID is included in the token’s signed response to confirm that the same TLS channel session from the server’s first communication with the browser is used.
U2F also supports device attestation which is not discussed in this post [3].
U2F Areas for Improvement
While U2F includes features to protect against common phishing and MITM attack, the protocols used in production still have some areas that could be improved which are highlighted by Dauterman et. al [4]:
Many U2F tokens use a global authentication counter across all services. This global counter value could potentially be used to track a user authenticating at various services if service providers colluded.
If a token is faulty or compromised during a supply chain attack, then the user loses out on U2F security guarantees.
True2F
Dauterman et. al. propose True2F, a two-factor authentication system that provides user protection even in the presence of compromised tokens, as an improvement over U2F. Instead of solely relying on the token while executing the challenge-response protocol with the server, True2F has the token and browser collaborate in order to respond to a server. As long as the user’s browser is not compromised, the user can still securely authenticate with services even if the token is compromised. Then, once the token is discovered to be compromised, it can be discarded.
True2F leverages a few additional cryptographic primitives not used in U2F. and we will touch on the following:
Verifiable random functions (VRFs) [5]
Collaborative key generation
Firewalled ECDSA signatures
Note: The use of these primitives do not cover the entirety of the paper’s contributions. The paper also describes a log data structure for minimizing storage requirements while still mitigating the privacy risk of using a global counter among other topics.
True2F Key Generation
Instead of defining a master key pair as a single ECDSA key pair, True2F defines a master key pair as:
A master public key composed of a ECDSA public key and a VRF public key
A master secret key composed of a ECDSA secret key and a VRF secret key
When initializing a token, the token and the browser will execute the following collaborative key generation protocol [4]:
The browser randomly samples a value from the elliptic curve group. The browser sends a commitment to .
The token randomly samples its own value from the elliptic curve group. The token sends to the browser where is the curve generator.
The browser opens its commitment and reveals . Then, the browser generates the public key as or .
The token verifies that corresponds to the browser’s commitment. If browser’s commitment opening is valid, the token accepts the public key as and uses as the secret key.
The collaborative key generation protocol can be used to generate the full master key pair such that upon completion, the token has the master secret key and the browser has the master public key.
True2F Registration
True2F introduces verifiable identity families (VIFs), a method for deriving multiple ECDSA key pairs from a single master key pair [4]. A token and browser can use this method such that the browser can verify that the token correctly generated the ECDSA key pair. The browser is not able to audit the token’s operations in this manner in U2F.
The VIFs described in the True2F paper use VRFs which is why the master key pair contains a VRF key pair. During registration, the token, the browser and the server execute the following steps [4]:
The server sends an application ID.
The browser includes a random key handle when forwarding the server’s message to the token.
The token uses its VRF secret key and the key handle to generate a pseudorandom output and a proof . Recall that can be used in VRF verification along with the VRF public key to check that the output was correctly produced using the VRF secret key.
The token computes the identity public key by raising the master public key by and sends it to the browser with and .
The browser executes VRF verification using the VRF public key, the key handle, and . If VRF verification passes, the browser checks that the identity public key is equal to the master public key raised by .
If the checks in step 5 pass, the browser forwards the key handle and the identity public key to the server.
True2F Authentication
During authentication, the token, the browser and the server execute the following steps [4]:
The server sends an application ID, challenge and key handle.
The browser also includes an origin and TLS channel ID when forwarding the server’s message to the token.
The token uses the key handle, and its VRF secret key to generate the pseudorandom output . The token can derive the identity secret key by multiplying the master secret key by .
The token increments a local counter that tracks the number of authentications performed using the token.
The token and the browser execute a firewalled ECDSA signature protocol in order to produce the identity secret key’s signature over the application ID, challenge, origin, TLS channel ID and counter value which is sent to the server.
If the signature is valid for the registered identity public key, the origin and TLS channel ID are correct and the counter value is valid, the server accepts the token’s response.
The firewalled ECDSA signature protocol described in step 5 uses a cryptographic reverse firewall which is defined as a machine that modifies the messages of a user’s machine as it interacts with the outside world in an effort to secure the user against a compromised machine while still preserving the functionality of the underlying protocol [7]. In True2F, the browser serves as the firewall that prevents a compromised token from using bad randomness when producing signatures or leaking information using signatures. The protocol consists of the following steps [4]:
The token and the browser execute the collaborative key generation protocol previously described such that upon completion, the token has some value and the browser has a value .
The token uses as the random ECDSA nonce [6] when producing a signature.
The browser checks that the correct nonce was used to produce the signature.
The browser uses the token’s signature to produce another valid signature and sends it to the server.
As mentioned in a previous post, ECDSA verification requires the calculation of a point where is a nonce. In step 3, the browser checks that the correct value for is used. In step 4, the browser makes use of ECDSA signature malleability where both and are valid signatures to produce another valid signature to send to the server.
Conclusion
U2F utilizes the basic cryptographic building blocks of digital signatures and keyed one way functions to enable the use of hardware tokens for two-factor authentication systems resistant to phishing and MITM attacks. True2F attempts to improve U2F by introducing a few new building blocks that allow a user’s browser to participate in protocols thereby protecting the user from compromised tokens. The paper is pretty interesting and worth a read!
For many developers, digital signatures (and most cryptographic primitives for that matter) are black boxes that “just work”. Developers can usually expect to be able to leverage open source implementations for signature generation and verification either in a programming language’s standard library or in a third party library. Oftentimes, all it takes is a quick skim through the API documentation and within minutes a developers can drop signature generation and verification into their systems.
While easier to use digital signatures can be a blessing, it is not necessarily always the case that digital signatures are easy to securely use. Furthermore, not all documentation is created equal and in some cases documentation might lack the proper guidance to ensure developers can use digital signatures in a secure manner. As a result, understanding how digital signatures can be incorrectly used is valuable knowledge for developers.
In this post, we will explore incorrect usage of the Elliptic Curve Digital Signature Algorithm (ECDSA). If you are unfamiliar with ECDSA, Andrea Corbellini has written a great introductory primer.
Pitfall #1: Signature Malleability
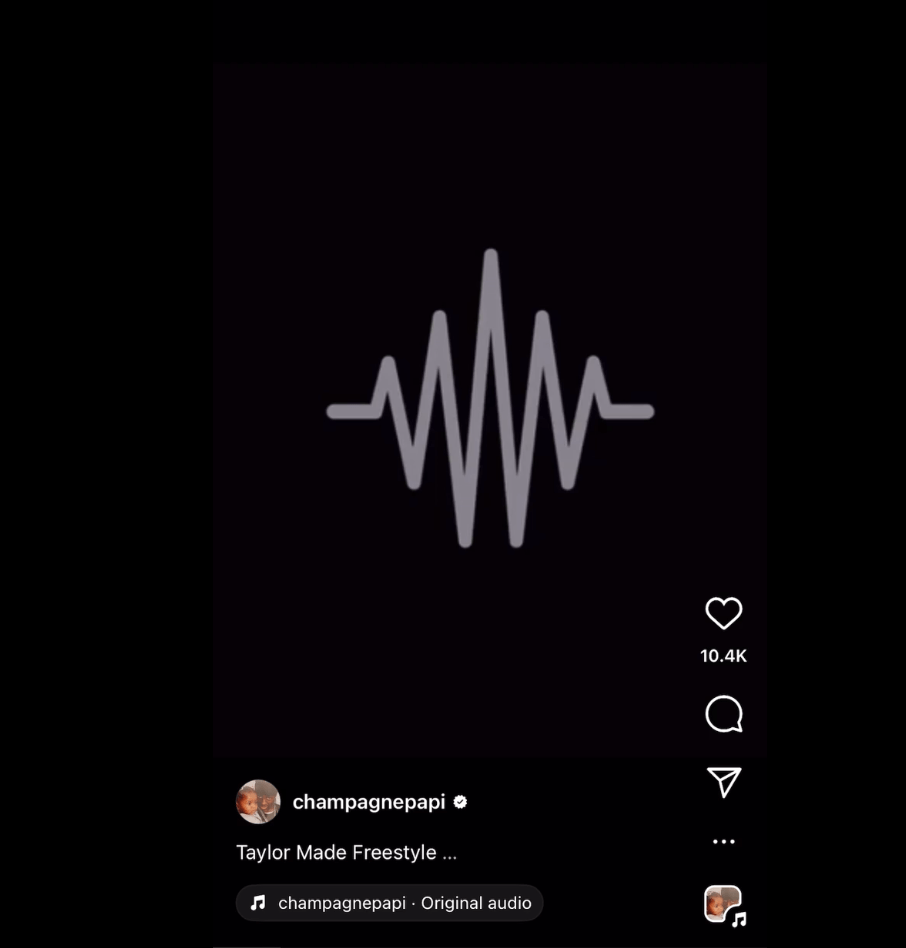
Recall that a ECDSA signature is valid for a public key and hash if is the x coordinate of the following point calculated by the verifier:
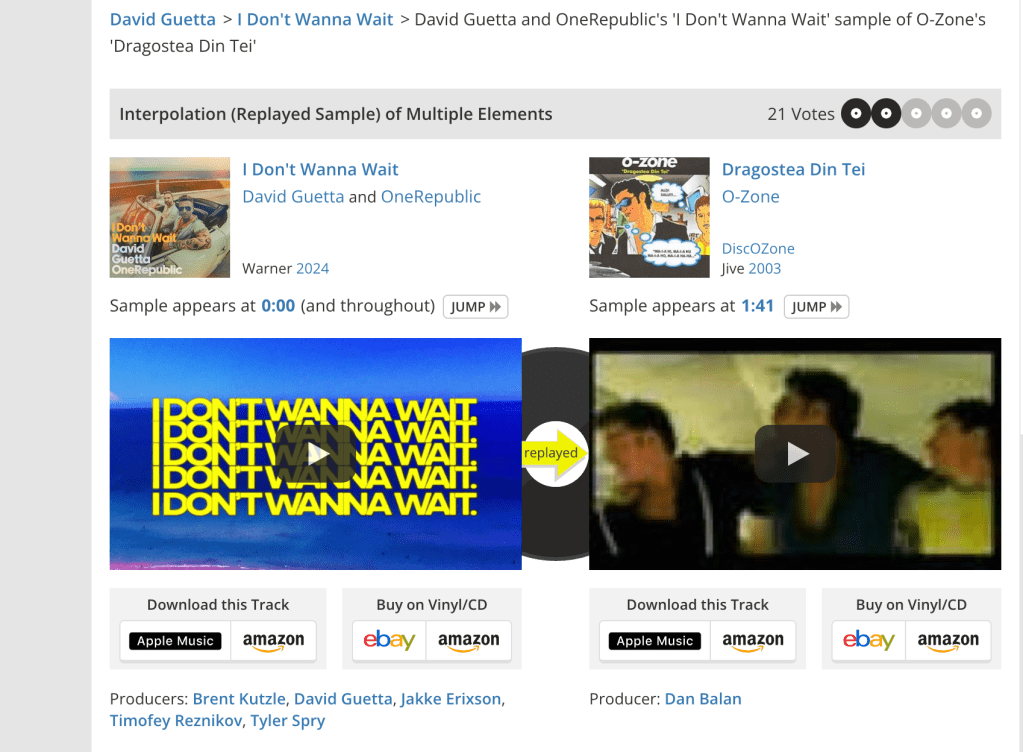
Notice that signature verification will pass as long as is correct – is used in the calculation of point , but as long as the x coordinate of is equal to , the actual value for does not matter. Thus, if there is more than one value for that can result in a point with an x coordinate equal to then there can be more than one valid signature for a given public key and hash. In fact, since is a point on an elliptic curve, there is also a point on the curve with the same x coordinate as , but a negated y coordinate [1]. Since [7] and is an input into the calculation of , a negated results in which has the same x coordinate as . As a result, both and are valid signatures for the public key and hash . We refer to as a “malleable” signature because a third party can use it to compute another valid signature for a public key and hash without access to the signing private key.
This malleability property of ECDSA signatures can introduce security vulnerabilities into systems if:
Replay defense mechanisms use the signatures themselves as unique identifiers (i.e. a verifier should only allow a signature to be used once).
Software relies on signatures as identifiers to query for additional information. See Bitcoin transaction malleability [2].
Avoiding Pitfall #1
One solution to defend against signature malleability based attacks is to enforce a single canonical signature for a given public key and hash which is the approach taken by Bitcoin. More specifically, the Bitcoin core client software will only accept “low s-value” ECDSA signatures where a signature has a low s-value if is less or equal to half the curve order [3]. The secp256k1 curve library used by the client will always generate signatures in low s-value form and the verifier expects provided signatures to also be in low s-value form [4].
Another solution is to avoid using signatures in identifiers or at the very least making sure to use unique values in the identifier creation process i.e. a nonce in the signed message. Unless there is a single canonical signature for a given public key and hash, signatures cannot be relied upon as unique identifiers.
Example Code for Pitfall #1
Example code for creating malleable signatures can be found here.
The program first generates the original signature and then TrickSig1() is used to create another valid signature. In the first attempt, the signature generated by TrickSig1() passes verification. However, in the second attempt, the ECDSA verification implementation from go-ethereum is used which implements the low s-value requirement thus causing verification to fail.
original sig: (0xe742ff452d41413616a5bf43fe15dd88294e983d3d36206c2712f39083d638bd, 0xe0a0fc89be718fbc1033e1d30d78be1c68081562ed2e97af876f286f3453231d) original sig verification with message hash 0xb94d27b9934d3e08a52e52d7da7dabfac484efe37a5380ee9088f7ace2efcde9: SUCCESS
trick sig 1: (0xe742ff452d41413616a5bf43fe15dd88294e983d3d36206c2712f39083d638bd, 0x1f5f0376418e7043efcc1e2cf28741e252a6c783c21a088c3863361d9be31e24) NO MALLEABILITY CHECK trick sig 1 verification with message hash 0xb94d27b9934d3e08a52e52d7da7dabfac484efe37a5380ee9088f7ace2efcde9: SUCCESS
WITH MALLEABILITY CHECK HALF CURVE ORDER = 7fffffffffffffffffffffffffffffff5d576e7357a4501ddfe92f46681b20a0 trick sig 1 s-value <= half curve order! normalizing sig by negating s-value trick sig 1 verification with message hash 0xb94d27b9934d3e08a52e52d7da7dabfac484efe37a5380ee9088f7ace2efcde9: FAILED
Pitfall #2: Verification Without Hash Pre-Image
Many ECDSA verification implementations expect the hash of the signed message as input, but the the verifier should always be the one to hash the message and should never accept a hash without knowledge of its pre-image [5]. Otherwise, an attacker is able to pick the hash that will used for verification. If the attacker does not need to know the pre-image of the hash, he/she can pick a hash that he/she can always produce valid signatures for [6].
The point calculated during verification can be expressed as where and .
We can express in terms of and :
We can express in terms of , and :
We can express a valid signature as:
Thus, if an attacker has the freedom to choose the value for hash , then it can set and to arbitrary non-zero values and then derive values for hash and signature that would always pass verification for a public key .
Avoiding Pitfall #2
The solution to defend against this type of attack is to implement verifiers to always use the result of hashing a received message (that another party is claiming to have signed) for ECDSA verification.
Example Code for Pitfall #2
Example code for exploiting ECDSA verifiers that do not know the pre-image of a hash can be found here.
The program uses TrickSig2() to create a valid signature and hash pair given a public key. The verifier just accepts the hash so it has no knowledge of the pre-image (in contrast to if the verifier instead hashed the input before running the verification algorithm).
trick sig 2: (0x41b5201d06acaafb67785a8e8aa89626e79c2117acce468196c1c5074ec9c274, 0x4f28c5a75abedce19cacba086282632f175abb635bd633465f6763a250eea629) trick sig 2 verification with message hash 0x8bcbdc44c5ba50680f5fa229ec8befecba16cc0a1be660241d32939ec472fd8c: SUCCESS
Conclusion
Both of the described pitfalls are examples of instances where a developer that has access to an easy to use cryptographic primitive library (both code examples import widely used open source implementations either from a standard or third party library) could still incorrectly use the library thereby losing some of the security properties of the primitive. Especially when creating systems that require cryptographic guarantees, developers stand to benefit a lot from not only a larger breadth of tools, but also a better understanding of what correct (or incorrect) usage of those tools looks like.








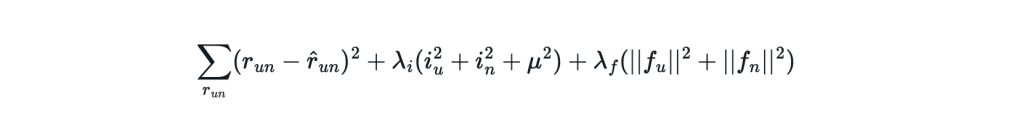
 from the elliptic curve group. The browser sends a commitment to
from the elliptic curve group. The browser sends a commitment to 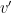 from the elliptic curve group. The token sends
from the elliptic curve group. The token sends 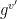 to the browser where
to the browser where  is the curve generator.
is the curve generator. or
or  .
. as the secret key.
as the secret key. and a proof
and a proof  . Recall that
. Recall that  and the browser has a value
and the browser has a value 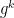 .
.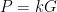 where
where 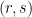 and
and 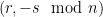 are valid signatures to produce another valid signature to send to the server.
are valid signatures to produce another valid signature to send to the server. and hash
and hash  if
if  is the x coordinate of the following point calculated by the verifier:
is the x coordinate of the following point calculated by the verifier:
 is used in the calculation of point
is used in the calculation of point  , but as long as the x coordinate of
, but as long as the x coordinate of 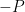 on the curve with the same x coordinate as
on the curve with the same x coordinate as  where
where 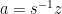 and
and 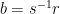 .
.  and
and 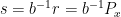
 ,
,