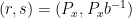Along with questions from an initial dive into the 2.0 spec.

This essay and all new writing is also published in my newsletter which you can sign up for here.
We’re just a few months into 2024 and there does not appear to be any sign of slow down in generative AI advancements with the quality of synthetic media increasing every day across all modalities. As election seasons progress throughout the world, we can expect to see an uptick of synthetic deepfakes making their rounds online and with it increased concerns of how to distinguish between physical and AI generated realities.
In the past few months, C2PA, touted as a technical standard for establishing the provenance of digital media, has received increased attention as a potential solution with a number of tech companies including Meta, Google and OpenAI shipping integrations or announcing plans to do so. Adobe has been leading the charge promoting the use of Content Credentials, built using C2PA, as “nutrition labels” that can be used by consumers to understand the provenance of media and most importantly distinguish between real media and AI generated deepfakes. At the same time, the approach has been criticized for being too easily bypassed by bad actors and insufficient for proving provenance.
As the standard is evaluated and adopted, it is worthwhile asking: what are the exact problems that the C2PA standard actually solves for and what does it not solve for?
What is C2PA?
From the C2PA website:
The Coalition for Content Provenance and Authenticity (C2PA) addresses the prevalence of misleading information online through the development of technical standards for certifying the source and history (or provenance) of media content.
From the C2PA spec:
This specification describes the technical aspects of the C2PA architecture; a model for storing and accessing cryptographically verifiable information whose trustworthiness can be assessed based on a defined trust model. Included in this document is information about how to create and process a C2PA Manifest and its components, including the use of digital signature technology for enabling tamper-evidence as well as establishing trust.
My simplified explanation of C2PA in a single sentence:
C2PA is a standard for digitally signing provenance claims about a media asset (i.e. image, video, audio, etc.) such that any application implementing the standard can verify that a specific identity certified the claim.
A claim consists of a list of assertions about an asset which can include:
- The creator’s identity
- The creation tool (i.e. camera, Adobe Photoshop, OpenAI’s DALL-E 3)
- The time of creation
- The “ingredient” assets used and actions performed on them during creation
A key property of C2PA is that a claim is directly tied to an asset and can travel with the asset regardless of where the asset is used whether it be on a social media platform (i.e. Facebook, Instagram) or a chat application (i.e. Whatsapp).
A claim is digitally signed by the hardware or software used to create the asset. The signature and claim are then packaged up into a manifest file that can be embedded into the asset and/or stored separately for later retrieval. An application can then fetch the manifest for an asset, verify the signer and evaluate the trustworthiness of the signer based on the requirements of the application. For example, Adobe’s Content Credentials Verify tool checks uploaded assets for a manifest and if the application trusts the signer the UI will display a Content Credentials badge.
But, how would an application know if the assertions in a claim are actually correct and that an asset was actually created using, for example, a camera and not a generative AI model? The short answer is that an application wouldn’t – the C2PA manifest for an asset alone is insufficient to guarantee that claim’s assertions are correct. So, what’s the point of a signed provenance claim if we can’t guarantee that its assertions are true?
Note: A C2PA workflow can provide stronger guarantees around the correctness of certain assertions, such as the creation tool, if a claim is signed by hardware with a secure enclave. In 2023, Leica released a camera with C2PA signing support which would allow the camera itself to sign a claim asserting that the specific camera model was used to take a photo. However, since hardware with C2PA signing support is not widely deployed as of early 2024, the rest of this post will focus instead on scenarios where claims are signed by software.
What does C2PA not solve for?
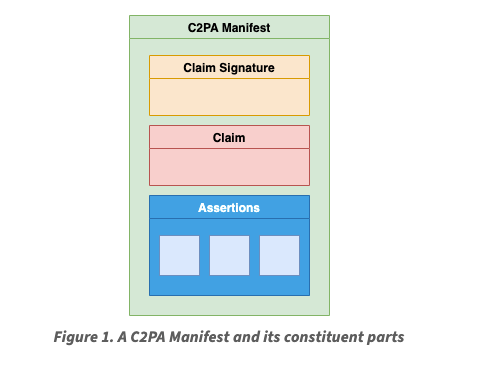
The trust model defined in the C2PA spec explicitly states that a consumer (both the human and an agent acting on behalf of the human) is able to verify the identity of the signer for a claim, but must decide on their own whether the claim’s assertions are correct using the signer’s identity and any other available information as evidence. Given this, the criticism that the use of C2PA alone would be unable to actually establish irrefutable provenance of an asset is fair – you cannot guarantee that a provenance claim for an asset accurately represents the asset’s provenance just based on signature verification alone.
What does C2PA solve for?
The problem that C2PA actually solves for is establishing non-repudiable attribution for provenance claims about a media asset in an interoperable manner. The claim signature links the claim to a specific identity which establishes attribution and non-repudiation – anyone can verify that the identity made the claim and not someone else. The standardized data model for the manifest that packages up a claim and its signature allows any application supporting the standard to process a claim and attribute it to an identity which establishes interoperability.
Is all of this still useful if the claim may not represent the asset’s true provenance? I would argue yes.
Today, as an asset is shared and re-shared across different platforms, the authentic context for the asset is lost.
Consider the following scenario: a photo taken from country A could be published by a news organization on social media and then copied and re-shared across accounts and platforms such that a consumer is misled by a third party to believe that the re-shared photo shows an event happening in the conflict zone of country B.
When the news organization publishes the photo they are making a claim that the photo was taken at a specific time and place. The claim is a part of the authentic context defined by the news organization. The problem is that this context is lost as the photo travels around the Internet making it more difficult for a consumer to determine who the photo was originally published by and allowing others to make claims about the photo that sow confusion.
A signed claim would not irrefutably prove that the photo was taken at a certain time and place, but it would preserve the authentic context for the photo – it would preserve the claim that the news organization made about the photo’s provenance. Consumers would still have to judge for themselves whether they trust the news organization’s claim, but they would know for certain who the photo was originally published by and that the claim was made by the news organization and no one else which keeps the news organization accountable for their claims.
Issues to address
A few issues come to mind that are worth addressing:
Many platforms strip metadata, which would include C2PA manifests, from uploaded media assets
Potential solutions to explore:
- Platforms can retain manifests for uploaded assets
- Publishers can store manifests in a public registry such that they can be looked up for assets even if platforms strip the manifest for uploaded assets
Bad actors can strip the C2PA manifest before uploading an asset
Potential solutions to explore:
- Platforms can start flagging assets without manifests and/or prefer assets with manifests in algorithmic feeds
The challenge here is that most assets will not have manifests initially similar to how most websites did not have SSL certificates during the early days of the HTTP -> HTTPS transition so before this becomes a viable approach it will need to be much easier for publishing tools to create manifests. The more aggressive warnings shown by browsers for websites without SSL certificates were enabled in large part by services like Let’s Encrypt dramatically reducing the friction in obtaining a SSL certificate.
Bad actors can create their own C2PA manifest with incorrect assertions for an asset
Potential solutions to explore:
- Platforms can use trust lists and scoring to evaluate whether the signer should be trusted in a specific context
Questions
A few questions I am thinking about:
How will the C2PA trust list that initial validator implementations will use by default be decided?
The current version of the C2PA spec uses a PKI based on x509 certificates. A claim signer must have a signing certificate and a validator will check that the signing certificate fulfills one of the following conditions:
- The signing certificate can be linked back through a chain of signatures to a root Certificate Authority (CA) certificate that is on the default C2PA list of trusted CAs
- The signing certificate can be linked back through a chain of signatures to a root CA certificate that is on the validator’s custom list of trusted CAs
- The signing certificate is on the validator’s custom list of trusted signing certificates
The members of the default C2PA trust list will have a lot of power because claims signed by signing certificates that they issue will be trusted by default by any C2PA software.
How will major content distribution platforms (i.e. Facebook, Instagram, etc.) with C2PA validator integrations decide on the trust anchors to add to their trust list?
The platforms will be able to customize their trust lists and specify additional CAs (and possibly ignore CAs on the C2PA trust list?) that they trust. But, in practice, will they just use the default C2PA trust list?
How will creator tools get signing certificates that are accepted by validators?
Will developers have to go through a manual approval process? Will this go through a small number of CAs or will there be many CAs that issue different types of certificates that reflect the type of validation performed similar to Domain Validated vs. Organization Validated SSL certificates? Will automated services be possible similar to what Let’s Encrypt did for SSL certificate issuance?
The claim signer is expected to be the hardware or software used to create an asset and not the creator themselves. In certain cases, could it make sense for the claim signer to be the creator themselves?
The Creator Assertions Working Group (CAWG) is working on standardizing how a creator can create a signed assertion documenting themselves as the asset creator in a C2PA claim. But, this results in an additional signature separate from the claim signature. The intent seems to be for the hardware or software based claim signer to verify this identity assertion before including it in the claim. This workflow makes sense in the scenarios where the hardware or software is not completely controlled by the creator i.e. a camera with a secure enclave, a backend service for a web application. However, this workflow makes less sense for non-hardware, locally run creator tools (applies to many open source tools) without a backend that can secure a private key for signing. In this scenario, since the creator is in complete control of the tool, it seems like it would make more sense for the claim signer to just be the creator rather than having a separate claim signature and an identity assertion – who else would produce the claim signature besides the creator?
Can identity assertions preserve privacy?
The CAWG seems to be exploring the use of privacy preserving techniques for future versions of the spec that are compatible with WC3 Verifiable Credentials. There is also interesting in the wild work happening in other communities that seems worthwhile to consider learning from. The 0xPARC community has established its own Proof Carrying Data (PCD) framework that uses ZKPs to create and compose privacy preserving claims about an identity – perhaps there is an opportunity to leverage some that work here.
How will content optimization pipelines that alter the hash of data without altering visual content (i.e. image rendering, video transcoding, etc.) be affected by C2PA adoption?
The C2PA spec allows service providers to create their own signed claims with assertions about the computation performed on an input asset which is referenced in the manifest. However, this would require service providers to implement C2PA support which likely would only happen if they are pressured by platforms to do so. A platform might just show users an optimized version of an asset with a hash that does not match the one in a C2PA manifest. The argument in defense of this practice would be that the user is trusting the platform anyway and the platform knows that the optimized asset it is showing users visually corresponds to the one referenced by the hash in the manifest.
How should we think about C2PA vs. NFT standards like ERC-721?
While C2PA and NFT standards both have a design goal of establishing attribution for provenance claims in an interoperable manner, they also differ in a number of ways:
- The C2PA spec is focused on standardizing how to make assertions about the lifecycle of a media asset while most NFT standards are more generic with their treatment of asset metadata.
- The C2PA spec optionally allows manifests to be timestamped by centralized Time Stamp Authorities while NFT standards assume that metadata is timestamped by a blockchain.
- A C2PA manifest records a provenance claim while a NFT records a provenance claim and links it with a transferrable/tradeable asset.
At this point, C2PA and NFT standards appear to be more likely to be complements as opposed to substitutes.
Can C2PA adoption benefit from the consumer crypto wallet infrastructure that has been deployed in the past few years?
In order for creators to create identity assertions for C2PA claims, they will need consumer friendly software for signing. While there are still a number of UX/UI improvements that need to be made, the consumer wallet software that the crypto industry has funded in the past few years arguably represents the most sophisticated deployment of consumer digital signing software out in the wild.
 from the elliptic curve group. The browser sends a commitment to
from the elliptic curve group. The browser sends a commitment to 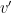 from the elliptic curve group. The token sends
from the elliptic curve group. The token sends 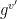 to the browser where
to the browser where  is the curve generator.
is the curve generator. or
or  .
. as the secret key.
as the secret key. and a proof
and a proof  . Recall that
. Recall that  and the browser has a value
and the browser has a value 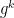 .
.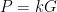 where
where 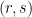 and
and 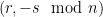 are valid signatures to produce another valid signature to send to the server.
are valid signatures to produce another valid signature to send to the server. and hash
and hash  if
if  is the x coordinate of the following point calculated by the verifier:
is the x coordinate of the following point calculated by the verifier:
 is used in the calculation of point
is used in the calculation of point  , but as long as the x coordinate of
, but as long as the x coordinate of 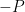 on the curve with the same x coordinate as
on the curve with the same x coordinate as  where
where 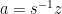 and
and 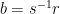 .
.  and
and 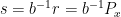
 ,
,