How does X’s community fact-checking system actually work?
This essay and all new writing is also published in my newsletter which you can sign up for here.
After Elon’s decimation of the X/Twitter’s previous content moderation systems, Community Notes (formerly known as Birdwatch) emerged from the ashes as one of the only members of the content moderation old guard that survived the company’s ownership transition
The community fact-checking system relies on existing X users to write and rate notes that add helpful context to misleading posts. In the current era of declining trust in centralized institutions for fact-checking politically polarizing topics, the system is designed to avoid relying on any single institution to define what is or is not a misleading post. Instead, it publicly attaches notes written and rated by users to posts based on an open source and publicly documented algorithm. While crowdsourced content moderation is not a new idea with various implementations deployed on other platforms (i.e. Wikipedia, Reddit), Community Notes uses a unique implementation that attempts to only surface notes if they are rated positively by users with diverse viewpoints (i.e. on the political spectrum).
First, the good news. On numerous occasions, Community Notes has successfully surfaced notes with very helpful context on misleading posts!
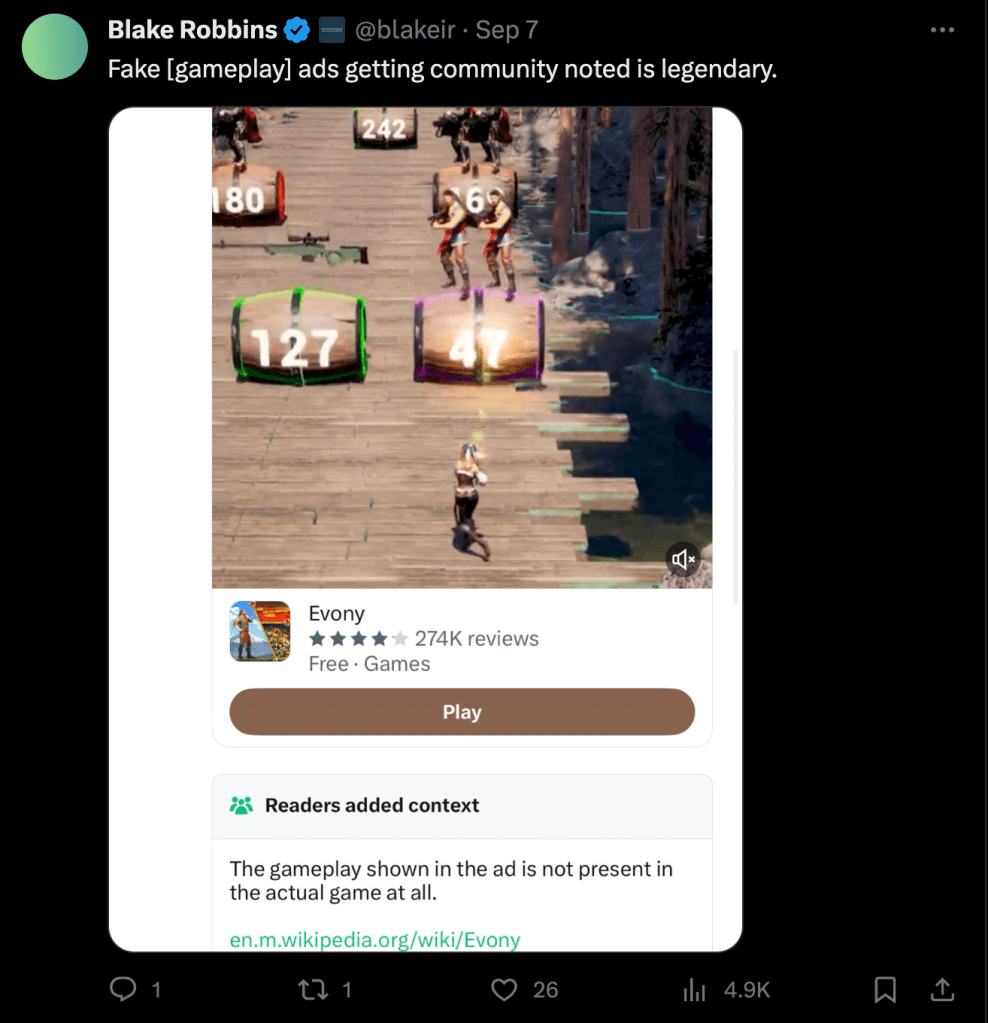

I think its probably fair to say that we’re collectively better off knowing that a game ad is a scam. And we’re also probably better off knowing that Elon did not unilaterally remove the verified badge from the New York Times’ profile in response to recent botched reporting even if it would make for a sensational story.
As an aside, if you ever wanted a feed dedicated to showing what happens when people are wrong on the Internet now you have Community Notes violating people for that.
Now, the bad news. On numerous occasions, Community Notes has also surfaced notes with incorrect information:
- On the lighter side, a post referring to Taylor Swift’s bodyguard’s Israeli military service was flagged by a note claiming the man is not her bodyguard. The man was later reported to in fact be her bodyguard.
- On the more serious side, a post with a video of an Hamas attack on Israelis was flagged by a note claiming the video was years old and not taken in Israel. The video was later reported to be real.
Furthermore, the volume of posts after the first 5 days of the Israel-Hamas war vastly outnumbered the volume of notes and assuming that a sizable portion of the posts included misleading claims or media it is likely that Community Notes failed to surface helpful notes for many misleading posts.
And the influence of Community Notes on the information landscape of X is poised to increase as keyboard wars shift from the feed into the Community Notes rating process and as the scope of impact of notes is expanded:

Making matters worse, even though X has lengthy documentation and a research paper describing the open source algorithm for ranking and surfacing notes, it is not clear how many people actually understand or trust how the algorithm is supposed to work.
A few notable quotes from a recent Wired article:
However, the system at least previously employed a technique known as bridge-based ranking to favor notes that receive positive interactions from users estimated to hold differing viewpoints. Still, how this works is not clear to at least some Community Notes contributors.
“I don’t see any mechanism by which they can know what perspective people hold,” Anna, a UK-based former journalist whom X invited to become a Community Notes contributor, tells WIRED. “I really don’t see how that would work, to be honest, because new topics come up that one could not possibly have been rated on.”
The reality is that the average user of X or Community Notes is not going to read pages of LaTeX equations and algorithm specifications to understand why a note is or is not surfaced on a post when they can just yell at Elon instead. At the same time, while it is unrealistic to expect the average user to understand nitty gritty technical details, there is value in equipping more people with a high level understanding of what the algorithm attempts to accomplish and the inputs that it depends on. If Community Notes (or any other community content moderation system for that matter) expects to build more user trust than the centralized institutions they aim to improve on then a prerequisite is to help people understand why their algorithmic approach should deserve that trust which requires more than transparency via open source code and documentation. It requires a diverse array of explanations for the diverse array of users that will engage with and be impacted by the system each constructed using terms and language appropriate for a specific target audience.
With this in mind, the aim of this essay is to make a small contribution to the array of explanations by answering the question of how does the Community Notes algorithm work under the hood?
How Community Notes works
At this point, we’re all accustomed to personalized algorithmic feeds on every social media platform that act as a filtered lens to view the stream of social consciousness flowing through the platform. On X, the For You feed gives each of us a unique view on what is happening. A side effect of this unique view is that the notion of shared truth becomes fuzzy because the whole point of the For You feed is to create a stream of information tuned to you which need not be the same as that of your next door neighbor. Concerns of society trending towards a world without any shared truth are abound.
Community Notes breaks from this trend. A note attached to a post is seen by everyone on X that sees the post. There is no personalized filtering here. The same note that is seen by coastal elites dunking on each other over the latest current thing is seen by your grandma that is still asking you to accept her Facebook friend request. But, if there is no personalized filtering, then how do you determine which notes to attach to a post for everyone to see? I probably shouldn’t be able to arbitrarily attach notes to Elon’s posts asking his followers to send me 1 ETH in exchange for 2 ETH.
The Community Notes algorithm only attaches a note to a post if the note is deemed to have a high likelihood of being seen as helpful by a broad set of users with diverse viewpoints. Thus, the core problem that Community Notes attempts to solve is: how do you predict whether a note will be helpful to a broad set of users with diverse viewpoints?
Before diving into how Community Notes attempts to solve this problem, let’s take a step back and consider a simpler version of the problem. If we put aside the “helpful to a broad set of users with diverse viewpoints” requirement and squint, the end result feels similar to the recommendation problem of: how do you predict whether a note will be liked by a user?
You’ve almost certainly benefited from solutions to versions of this recommendation problem in your day-to-day life:
- TikTok answers the question of how do you predict whether a video will be liked by a user so that you can endlessly scroll through your feed.
- Netflix answers the question of how do you predict whether a movie/show will be liked by a user so that you never run out of content to binge watch.
- Spotify answers the question of how do you predict whether a song will be liked by a user so that you can find new music to listen to.
The general form of the these recommendation problems is: “how do you predict whether an item will be liked by a user?”. And it turns out there is a general machine learning solution to this problem called collaborative filtering.
Collaborative filtering
The core idea of collaborative filtering is to predict whether a user will like an item by using data on whether similar users like the item.
What does this look like? As of last summer, I had never listened to Lindsey Sterling before. But, my friend Ian and I both really like orchestral film scores, and he happened to be listening to Sterling’s version of the main theme from The Dark Knight Rises on repeat around that time. Not all of Sterling’s music exactly fits the category of orchestral film scores, but it would be a reasonable bet for Spotify to recommend Sterling to me just based off of Ian’s preferences and our previous overlap in taste.
Let’s walkthrough how a very simplified version of Spotify might make that recommendation. First, we can visualize user preferences in the following table:

Each row in this table corresponds to a user and each column corresponds to an artist. If the cell contains a 1 then the user for that row likes the artist for that column. The cell for Yondon/Ramin Djawadi contains a 1 so Yondon likes Ramin Djawadi. The cell for Ian/Drake contains a -1 so Ian dislikes Drake. A blank cell indicates that the user has not explicitly expressed whether they like or dislike the artist. The objective is to fill in the blank cells based on the already filled in cells.
While we don’t know the specific reasons why each user likes a particular artist, we can assume that they exist and we just don’t know what they are. A simplified way to think about these reasons is: I like characteristic X, Y and Z and this artist exhibits a lot of characteristic X, Y and Z therefore I like the artist. In the context of music, these characteristics might be X = contains violin, Y = contains piano and Z = high energy. The technical term for one of these unknown characteristics is a latent factor.
Each user and artist has a vector of latent factors which can be used to determine how good of a match they are. The larger the numerical value for a latent factor, the more prominent the characteristic – for a user, this would mean a stronger preference for the characteristic (i.e. music that contains violin) and for an artist, this would mean a strong expression of the characteristic. A compatibility score for a user and artist can be computed using the dot product of their latent factors which is the sum of the product of each of the factor values. The intuition here is that since the largest dot product is achieved if the latent factor values for both the user and artist are large we can use the dot product as a singular value to represent how compatible the user and artist are.
Suppose:
- Yondon’s latent factors are represented by the vector [0.8, 0,9, 0.7]
- Sterling’s latent factors are represented by the vector [1.0, 0.6, 0.8]
- Rick Ross’ latent factors are represented by the vector [0.2, 0.5, 0.8]
The dot product for Yondon and Sterling is (0.8 * 1.0) + (0.9 * 0.6) + (0.7 * 0.8) = 1.9. Meanwhile, the dot product for Yondon and Rick Ross is (0.8 * 0.2) + (0.9 * 0.5) + (0.7 * 0.8) = 1.17. Based on these dot product values, we can infer that Yondon and Sterling would be more compatible than Yondon and Rick Ross.
But, we wouldn’t want to just rely on the dot product of latent factors for predicting whether a user would like an artist because the dot product only tells us how compatible a user and artist are based on preferences for characteristics without capturing whether a user generally likes or dislikes most artists and whether an artist is generally liked or disliked by most users. If Ian has similar preferences as me and he generally is neutral on most artists, then it could make sense to recommend artists that he likes to me. But, if Ian generally likes most artists, then it might not make as much sense – I could end up being recommended an artist that he likes not because of characteristic based compatibility, but because he just likes a lot of artists. Additionally, if Sterling is liked by Ian and she is generally neutral for most users, then it could make sense to recommend her to me. But, if Sterling generally is liked by most users, then it might not make as much sense – I once again could end up being recommended an artist based on general positive sentiment instead of characteristic based compatibility.
In order to capture this additional information, we can use a numerical value to represent a user’s likelihood to like most artists and an artist’s likelihood of being liked by most users. The larger the numerical value, the more likely a user is to like most artists and an artist is of being liked by most users. The technical term for this value is a bias or intercept (the Community Notes documentation uses the term intercept so we will use that here as well). Each user and artist has an intercept value which can be added to the dot product of their latent factors to output a compatibility score that not only captures compatibility based on characteristics, but also the user’s general sentiment towards artists and the artist’s general reception amongst users.
Now, suppose:
- Yondon is a grouch and generally dislikes new music he discovers so he has an intercept of -0.6
- Sterling is a hit with almost everyone that discovers her so she has an intercept of 0.7
- Rick Ross is polarizing and is a hit or miss for users that discover him so he has an intercept of 0.1
The updated score score for Yondon and Sterling is 1.9 + (-0.6) + 0.7 = 2. Meanwhile, the updated score for Yondon and Rick Ross is 1.17 + (-0.6) + 0.1 = 0.67. Based on these scores, we can not only infer that Yondon and Sterling would be more compatible than Yondon and Rick Ross, but that the former is also much compatible than the latter when also considering the user’s general sentiment towards artists and the artist’s general reception amongst users.
So, we know that the latent factors and intercept values for users and artists can be used to predict compatibility, but we’re still left with a problem: we don’t know what the actual latent factors and intercept values for users and artists are! This is where the learning part of machine learning comes into play. We need to create a model that learns parameter values (i.e. latent factors and intercept values for users and artists) so they can be used to output predictions of whether a user would like an artist.
At a high level, the training of the model consists of:
- Set the parameters to initial values (i.e. random).
- Repeat the following using a gradient descent iterative optimization algorithm:
- Calculate the prediction for each user/artist pair using the parameters.
- Calculate the loss which is a function of the difference between the actual rating for a user/artist pair and the prediction.
- Adjust the parameter values based on the loss with the goal of decreasing the loss in the next iteration.
This approach to collaborative filtering is called matrix factorization.
Community Notes core algorithm
We can also use matrix factorization to solve the problem “how do you predict whether a note will be liked by a user?”. The only difference is that artists will be replaced with users as shown in the table below:

Each row in this table corresponds to a user and each column corresponds to a note. A 1 indicates a user rated a note as helpful, a 0 indicates unhelpful and a 0.5 indicates somewhat helpful.
But, Community Notes is not designed to give personalized note recommendations so the goal is not to just predict whether a note will be liked by a user. We previously tabled the “helpful to a broad set of users with diverse viewpoints” requirement which still needs to be addressed.
The key insight that the Community Notes algorithm builds upon is that if a model is trained to explain note ratings as much as possible using user and note latent factors vs. intercept values then the model is encouraged to learn note intercept values that represent a note’s likelihood to be rated helpful by a broad set of users with diverse viewpoints. Recall that the dot product of latent factors represent compatibility based on specific characteristics. Given that a significant percentage of posts on X focus on politics and news, the specific characteristics that cause a user to rate a note as helpful or unhelpful regardless of how it is received by the majority of users might look like: aligns with a belief of the political left, aligns with a belief of the political right, etc. In other words, the user latent factors would end up capturing a user’s strength of preference for a political viewpoint and the note latent factors capture a note’s strength of expression of a political viewpoint.
Since the numerical values for latent factors can be positive or negative, we can visualize the range of values for a latent factor along an axis where moving towards the left means more negative values and more alignment with some viewpoint A while moving towards the right means more positive values and more alignment with some viewpoint B.

While viewpoints A and B might represent the political left and right respectively, the model does not actually explicitly associate viewpoint A or B with any particular definitions. However, just knowing whether users and notes align with A or B is sufficient for understanding whether a user and note are compatible based on viewpoint.
The intuition is that if a model trained to try to first explain note ratings using viewpoint compatibility using the user and note’s latent factors then:
- A note with many helpful ratings that are mostly explained by viewpoint compatibility would be more likely to receive a small intercept value indicating that it is not broadly helpful and the note is instead only deemed as helpful if the note and rater are viewpoint compatible.
- A note with many helpful ratings that are not mostly explained by viewpoint compatibility would more more likely to receive a large intercept value indicating that it is broadly helpful and the note is deemed as helpful even when the note and rater are not viewpoint compatible.
And if the note intercept value has the property where it is large when the note is broadly helpful regardless of viewpoint compatibility, it can serve as a “helpfulness score” that predicts how helpful a note will be to a broad set of users with diverse viewpoints!
The Community Notes core algorithm can actually be viewed as a variant of the standard matrix factorization used for traditional recommendation systems with two important changes:
- The model is trained to mainly explain existing note ratings based on the dot product of latent factors before adjusting the intercept values.
- The output from the model that we care about is the note’s intercept value instead of the actual predicted rating from the model.
1 is accomplished by using a technique called regularization to apply a larger penalty to the training loss for adjustments to the intercept values vs. adjustments to the latent factors. We can see how regularization is applied in the loss function definition:
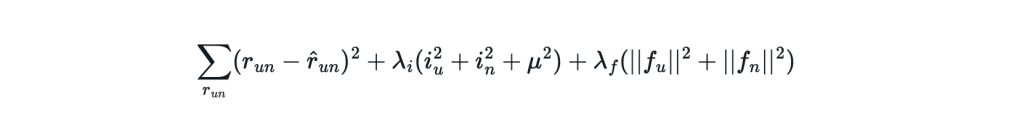
- The first term is the “base loss” which is calculated based on the difference between the actual and predicted ratings.
- The second term contains the intercept values which are multiplied by a regularization value that is 5x larger than that of the third term which corresponds to applying a greater penalty on the loss for the intercept values.
- The third term contains the latent factor values which are multiplied by a regularization value that is 5x smaller than that of the second term which corresponds to applying a smaller penalty on the loss for the latent factor values.
The result is that during training, the model will focus on adjusting latent factors to accurately predict existing ratings and only adjust intercept values as is needed as a last resort.
In summary, at a high level, the core algorithm is:
- Set the parameters to initial values (i.e. random).
- Repeat the following using a gradient descent iterative optimization algorithm:
- Calculate the prediction for each user/note pair using the parameters.
- Calculate the loss which is a function of the difference between the actual rating for a user/note pair and the prediction.
- Adjust the parameter values based on the loss with the goal of decreasing the loss in the next iteration.
- For each note, assign the its intercept value as its “helpfulness score”.
- Surface a note on a post if its helpfulness score meets the helpfulness score threshold requirements.
While Community Notes also incorporates additional mechanisms that are layered on top of this core algorithm, the ability for the system to incorporate diverse viewpoints when assessing whether a note will be helpful to a broad set of users comes from this core algorithm.
